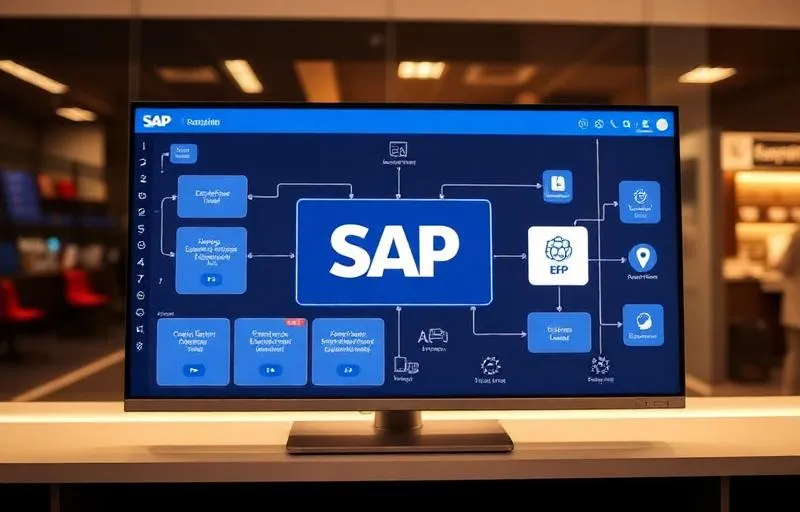
AWS Data Lake Architecture
Designed and deployed a serverless data lake on AWS processing 500GB of raw data daily with automated schema cataloguing and pay-per-query analytics.
The Challenge
A logistics SaaS company was generating 500GB of raw operational data daily — GPS telemetry, delivery events, vehicle sensor data — but had no way to query it cost-effectively. Storing it in RDS was prohibitively expensive at that volume; querying raw files on S3 was technically painful. Analytics were months out of date.
What We Built
We designed a serverless data lake using AWS native services. Raw data lands in S3 via Lambda ingest functions. AWS Glue crawlers automatically catalogue new data and update the schema registry. Athena provides SQL-on-S3 querying with no infrastructure to manage. A lightweight transformation layer (Glue Jobs) builds curated summary tables for the most common query patterns. CloudWatch monitors pipeline health.
How It Works
The company's data team had a real problem: they were sitting on a goldmine of operational data but couldn't query it without enormous cost or complexity. RDS couldn't handle the volume economically; spinning up and managing a Redshift cluster felt like overkill for their team size.
The architecture we designed is fully serverless. Raw data arrives via API and is ingested by Lambda functions that partition it by date, event type, and region before writing to S3 in Parquet format. This partitioning is what makes Athena queries fast — filters on partition keys skip irrelevant data entirely.
AWS Glue Crawlers run every hour, scanning new S3 partitions and updating the Glue Data Catalog. This means new event types or schema changes are automatically catalogued — the data team never manually defines table structures.
For the most common query patterns (daily delivery completion rates, vehicle utilisation by region, SLA breach analysis), we run nightly Glue Jobs that produce summarised tables. These pre-aggregated tables make the dashboards instant — no full table scans at query time.
The cost model was transformative. S3 storage costs a fraction of RDS at this volume. Athena charges per query scanned — with proper partitioning and Parquet compression, the average query scans 95% less data than it would on raw files. The entire data lake runs for roughly $800/month vs an estimated $6,000+ for equivalent RDS capacity.